Android之jemalloc
0x00 简单介绍
想调一个CVE、发现对jemalloc 了解太少。重新复习复习jemalloc,做个记录。
jemalloc最初是2005年 Jason Evans开发的新一代内存分配器, 之后没多久被添加到FreeBSD的libc中的默认内存分配器,用来替代原来的phkmalloc。2007年 Firefox Mozilla项目的独立版本也将jemalloc作为主要的分配器。2009年,Facebook 的后端项目也广泛使用jemalloc。2014年,Android 5 开始采用jemalloc作为主要的内存分配器,不过部分Android5/6依然能看到dlmalloc和jemalloc两者并存。
jemalloc的一些特性与设计原则:
强大的多核/多线程分配能力.
最小化的元数据开销
基于每个线程进行缓存,避免了同步问题。
避免了连续分配内存的碎片化问题。
简洁高效
0x01 结构
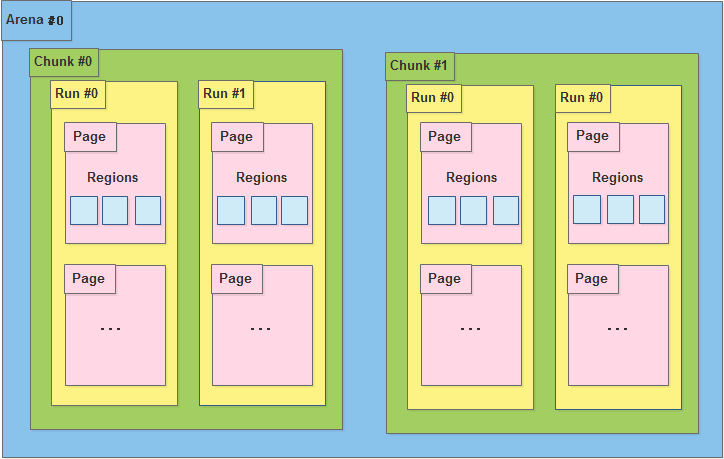
结构图
jemalloc对内存划分按照如下由高到低的顺序:
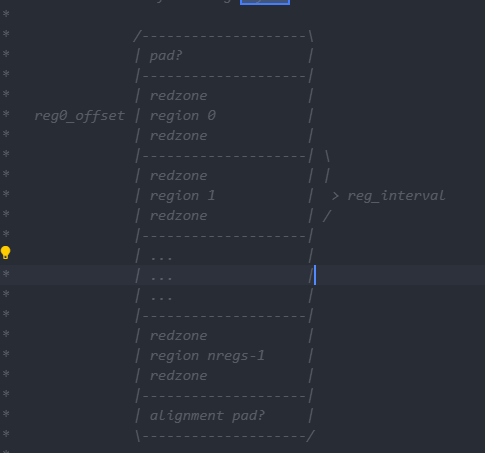
内存是由一定数量的arenas进行管理.一个arena被分割成若干chunks, 后者主要负责记录bookkeeping(记录信息).chunk内部又包含着若干runs, 作为分配小块内存的基本单元.run由pages组成, 最终被划分成一定数量的regions对于small size的分配请求来说, 这些region就相当于user memory.
arenas
对于Android来说:
限制了只使用两个arenas,每个带有一个lock。这意味着,不同线程尝试分配内存时,会循环、平均分配至两个arena,确保两个arena有大致相等的进程数量。只有在相同的arena中分配内存时才需要获取lock。
| |
用shadow查看arenas
chunk
一个arena下会有若干个chunk,Android 7之前chunk为256k,之后32位系统改为512k,64位系统改为2MB。
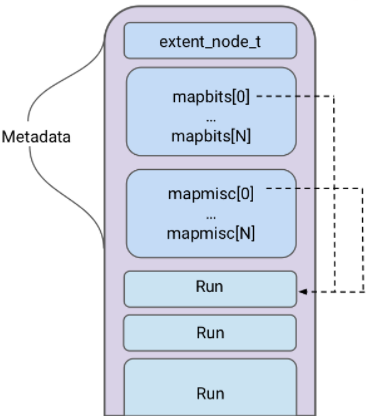
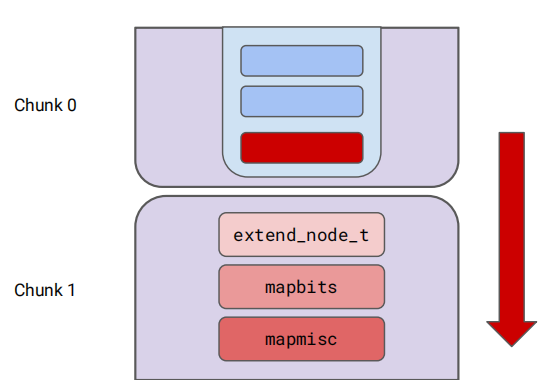
每个chunk都有一个chunk head 包含着这个chunk的元数据(metadata).Android 7之后元数据增加了mapbias与mapbits flags。
chunk是存放run的容器,大小固定相同,操作系统返回的内存被划分到chunk中管理
chunk中的元数据结构,mapbit[0]与mapmisc[0]指向chunk中的第一个run:
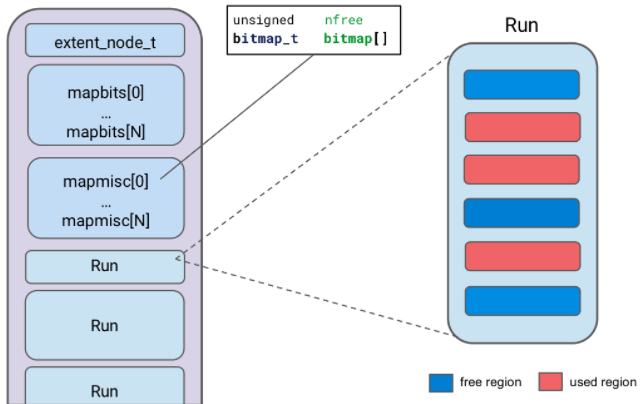
chunk元数据中mapmisc中的bitmap结构管理着run中的region的分配使用:
chunk
run
run是存放连续的大小相同的region的容器,每个chunk中会包含若干个run,而run的metadata会存放在chunk的header当中,这样region里只存放数据本身,不再有内存属性说明。
region
region是最小的存储单元,每个run里面的region大小完全相同,也没有元数据,malloc实际返回的是region的地址。
bins
jemalloc也用bin来管理内存,共有39个bins。bin的metadata存放于arena的header中,39个bin还会存放当前正在使用的run。所有带有空闲region的run和闲置的chunk信息会被放置在红黑树结构当中,这样寻找空闲内存的复杂度可以控制在o(log(n))。
tcache
为了优化多线程性能,jemalloc还采用了LIFO结构的tcache,存放近期被释放的region,每个线程的每个bin都对应一个tcache,存放在tcache中的内存并不会设置free标记位,并且由于tache附着于线程本身,使得大部分情况下从tcache分配内存时完全无需lock。
当jemalloc新分配一块内存是发现tcache为空,会触发prefill事件,此时jemalloc会将单前的arena上lock,并从当前run中取出一定数量的region存入tcache,保证tcache不为空。
当tcache满了(small bin是8,larger bin是20)的时候,会触发flush 事件,会释放部分region,并且才会被标记为已释放。这时这些region才能被其他线程自由分配。
此外,jemalloc也实现是GC机制。会有一个计数器统计申请和释放,达到阈值之后会触发特别的事件,目标bin里的tcache的四分之三的region会被释放掉。下次GC时会轮到下一个bin。这是可以从tcache中删除region并使其恢复常规可用性的另一种方法。
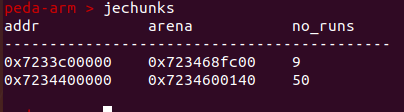
分配流程
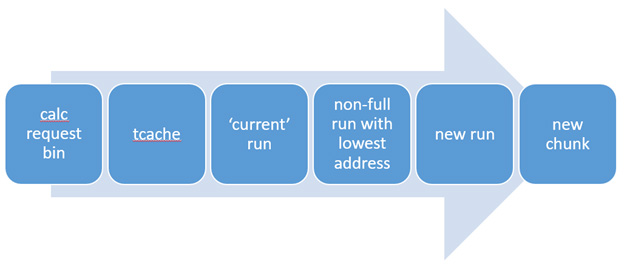
计算申请内存大小从当前线程的tcache中找到合适的bin如果tcache为空,就从当前的run中prefill一些region进来如果当前run耗尽,就从低地址开始找到第一个非空run如果现有run里没有足够的内存就分配一个新run如果chunk里没有空间了就分配一个新chunk,同时分配新run并prefill一些region到tcache
0x02 shadow
使用shadow查看Android中的内存布局,简单学习下shadow的使用
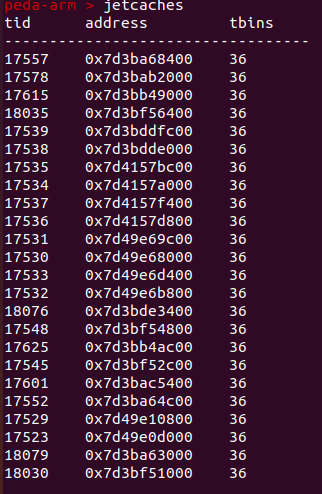
查看arenas
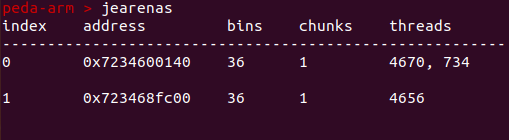
可以看到一共两个arenas,每个arena有36个bin,一共2个chunk。
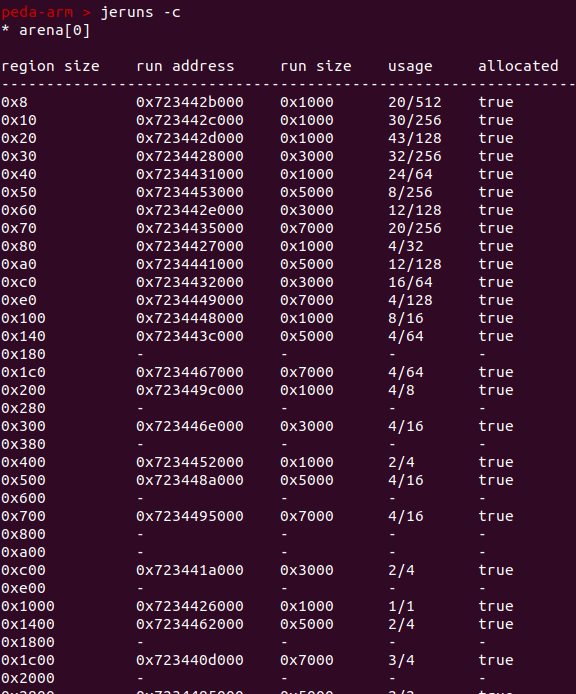
查看chunks
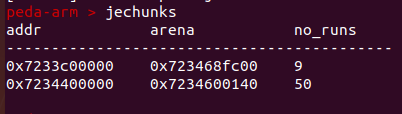
单个chunk,查看chunk中的run
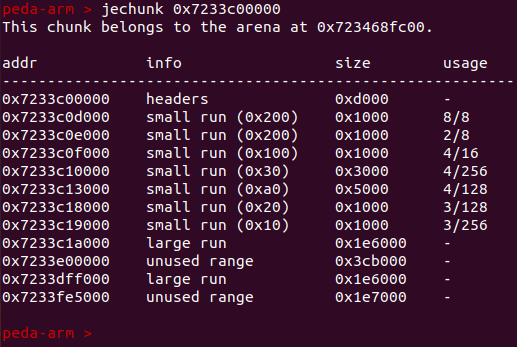
查看runs,会列出单前所有的run的详情 run_siez = region_size*no_regions
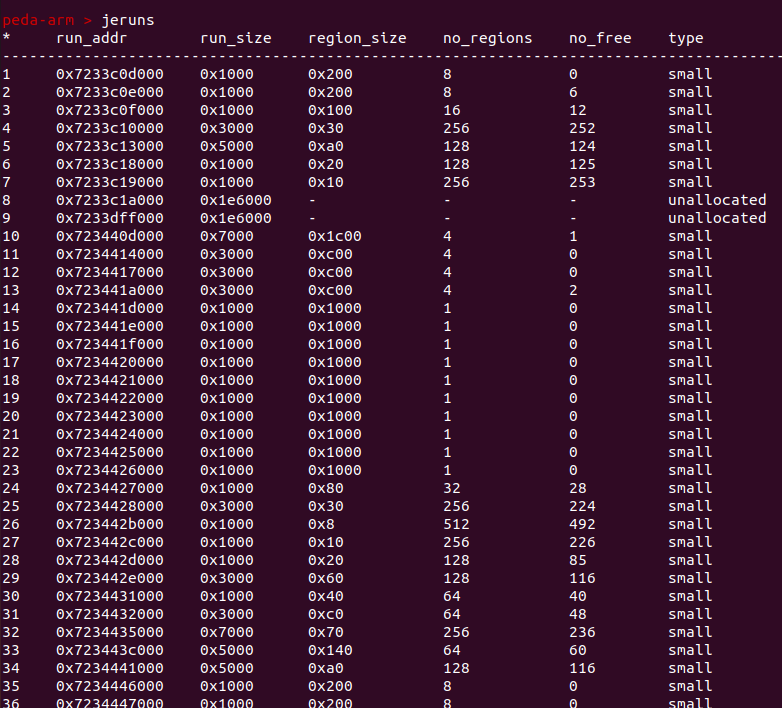
只显示单前运行中的run
是否是allocated状态是根据arena_chunk_map_bits_s 对应 bits的 第 [0] bit 来确定 这里jemalloc5 和 jemalloc4 3不一样。
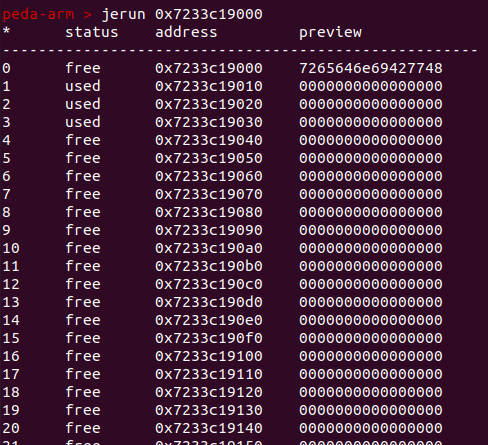
查看单个run的详情:
run的布局如下:
源代码arena.h中有很多关于bits之类的注释。能够帮助理解。
查看bins:
| |
runcur: 当前可用于分配的run, 一般情况下指向地址最低的non-full run, 同一时间一个bin只有一个current run用于分配.
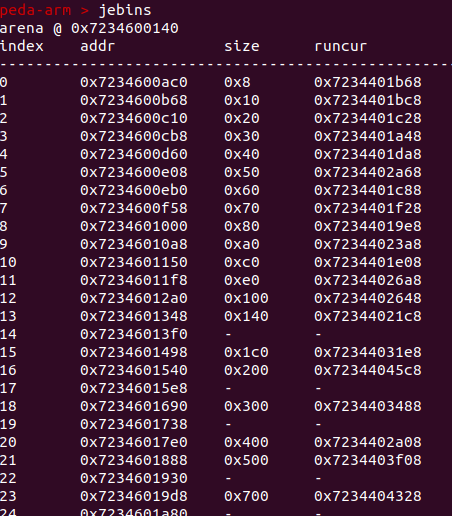
看别人的文章说是除去0号bin以外没4个bin为一组,组内size差一样,但是在这里可以看到每8个为一组,01-8号bin的size差值都为0x10,算是第一组,那第二组就为9-12号,只有4个bin size差值为0x20,但是有的为空,算第二组。没两组之间的差值2倍。以此类推,后面每4个为一组。
划分为{0}、{1-8}、{9-12}、{13-16}····· 可能不同版本会有区别。
查看regions [换了一个进程]
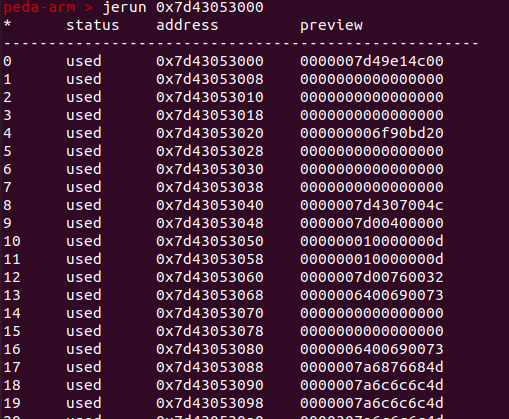
大小都是0x8
按大小查找:第4个:
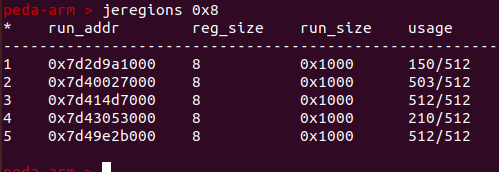
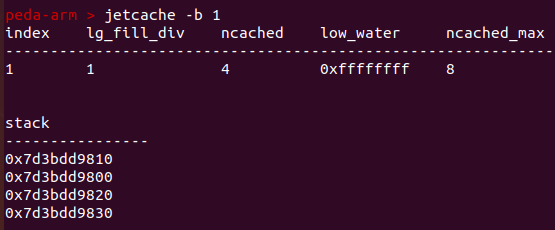
tchche查看:
tcache的定义:
| |

0x03 利用
堆溢出
一般先利用gadget 绕过ASLR,再利用gadget拿到代码执行的权限,只要能执行代码就能逃出sandboxing或者摆脱selinux。
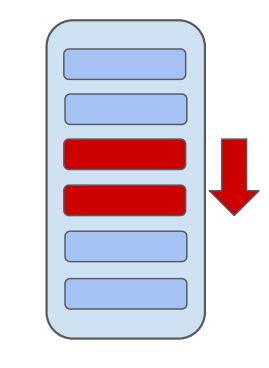
- Small region overflow
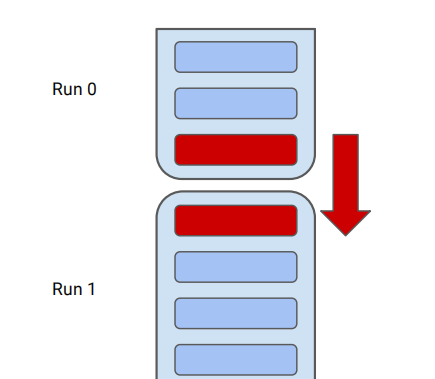
- Run overflow
- Chunk overflow
总结
后面还是得使用shadow工具具体调试CVE加深理解。
jemalloc新版与旧版有挺多区别,之后想要深入了解jemalloc的细节以及一些实现还是得看看源码。